
RoboVoxel: Inferring Soft-Body Physics from Videos (Under Review)
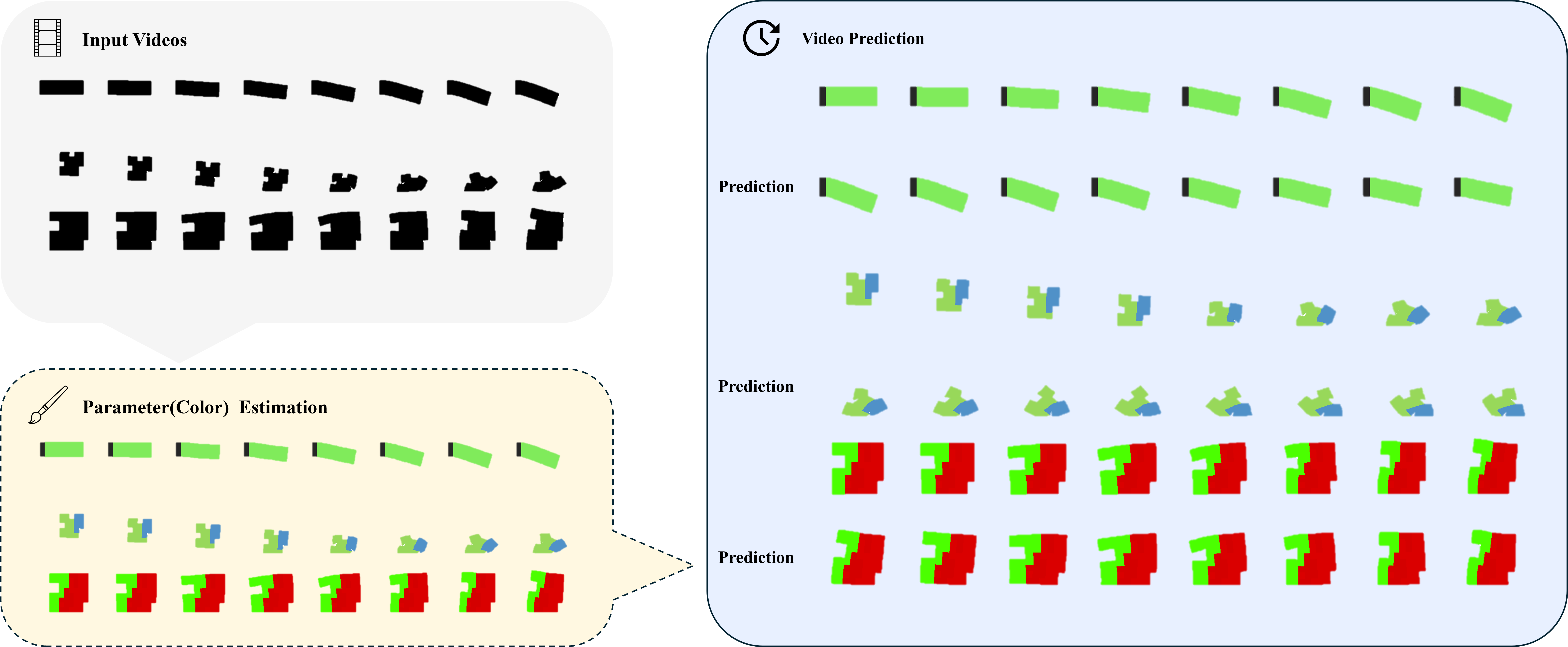
RoboVoxel is a project on learning voxel-level physical properties and actuator layouts of soft bodies directly from short grayscale videos.
Instead of hand-tuning parameters in a simulator, we ask a model to infer them from motion, and then check whether those inferred parameters can re-generate similar behavior.
Motivation
Rigid robots usually come with clean CAD models and well-documented masses, inertias, and joint limits.
Soft robots and deformable objects are very different:
- material properties can vary across space,
- large deformations and contacts are common,
- actuators may be embedded and not directly observable.
RoboVoxel explores the question:
Given a short video of a deformable body moving, can we guess the underlying material field and actuator placement well enough to reproduce its motion in simulation?
Core Idea
We reinterpret system identification as a kind of video-to-image translation:
- Input: a short grayscale video of a soft object or robot.
- Output: a single “parameter image”, where each pixel corresponds to a voxel in the simulator and each color channel encodes some physical quantity (e.g., stiffness, mass, damping, actuator direction).
This parameter image is then used as the input to a spring–mass simulator.
If the video rolled out by the simulator matches the original one, the inferred parameters are likely meaningful.
In short:
from gray motion → to colored physics → back to motion.
Method (High-Level)
The pipeline has three main pieces:
- Synthetic dataset with a modified simulator
- We modified a 2D spring–mass environment based on Evolution Gym.
- For many random beams, blobs, and soft robots, we generate:
- a grayscale motion sequence, and
- a color parameter image (used inside the simulator).
- Image decoder for parameter fields
- We train a convolutional autoencoding model (e.g., VAE-style) purely on parameter images.
- After training, we freeze the decoder so that it becomes a “renderer” from a low-dimensional latent vector to a full-resolution parameter field.
- Video transformer for inference from motion
- A video transformer (TimeSformer-style architecture) consumes the grayscale frames.
- It outputs a latent vector that is fed into the frozen decoder, producing the predicted parameter image.
- The model is trained with reconstruction losses on these parameter images.
To use the prediction for simulation, we optionally cluster or discretize the output values to obtain a set of material / actuator types, then run the simulation.


